Artificial Intelligence: Uses and Regulation By Local Government
Event date
Speakers
 Michael C. HorowitzCFR ExpertSenior Fellow for Defense and Technology Innovation, Council on Foreign Relations
Michael C. HorowitzCFR ExpertSenior Fellow for Defense and Technology Innovation, Council on Foreign Relations- Research Fellow, Council on Foreign Relations
Presider
 Vice President for National Program and Outreach, Council on Foreign Relations
Vice President for National Program and Outreach, Council on Foreign Relations
From State And Local Webinars.
Michael C. Horowtiz, senior fellow for defense technology and innovation at CFR, and Lauren Kahn, research fellow at CFR, discuss local government’s use and regulation of artificial intelligence and facial recognition technology.
Additional Resources
FASKIANOS: Welcome to the Council on Foreign Relations State and Local Officials Webinar. I’m Irina Faskianos, vice president for the National Program and Outreach at CFR. We’re delighted to have participants from forty-six U.S. states and territories with us for today’s discussion on “Artificial Intelligence Uses and Regulations by Local Government.”
This conversation is on the record, and we will circulate the audio and video and transcript after the fact.
As you know, CFR is an independent and nonpartisan membership organization, think tank, and publisher, focusing on U.S. foreign policy. CFR is also the publisher of Foreign Affairs magazine. Through our State and Local Officials Initiative, we serve as a resource on international issues affecting the priorities and agendas of state and local governments by providing analysis on a wide range of policy topics.
We’re pleased to have Michael Horowitz and Lauren Kahn with us today. We shared their bios, so I’ll just give you a few highlights.
Michael Horowitz is a senior fellow for defense technology and innovation at CFR. He is also the director of Perry World House, the Richard Perry Professor and professor of Political Science at the University of Pennsylvania. And previously Dr. Horowitz worked for the Office of the Undersecretary of Defense for Policy at the Department of Defense.
Lauren Kahn is a research fellow at CFR, where she focuses on defense innovation with a particular emphasis on artificial intelligence. Previously she was a research fellow at the Perry World House at the University of Pennsylvania.
And Lauren Kahn and Michael Horowitz co-authored the recent report, What Influences Attitudes about Artificial Intelligence Adoption: Evidence from U.S. Local Officials. And we’ve circulated that in advance of today’s discussion.
So thank you both for being with us. We appreciate it.
Michael, I want to start first with you to talk about your report and how state and local governments are using artificial-intelligence technology.
HOROWITZ: Well, thanks so much, Irina. And, you know, thanks to everybody tuning in. I’m really delighted to be here for the conversation. I know Lauren is as well, and you’ll hear from her in a minute.
And I want to just start by sharing my screen, if that’s OK, because I think that the story that Lauren and I want to tell you here is really a story that comes from some actual data that we gathered on how U.S. local officials are thinking about uses of artificial intelligence, both things like facial-recognition technology as well as self-driving cars, autonomous surgery, and a lot of other potential applications.
And so, to give you a sense of what I’m talking about here, our goal in doing this research was the insight that, you know, the United States is not like every other country. And, I mean, everybody on this call actually knows that already. But one of the ways that we’re not like every other country is our federal structure and the way that federalism in the United States empowers states and localities to make lots of really important policy decisions that often in other countries are made at the national level.
I mean, when we think about states and localities as laboratories for democracy, often that involves experimentation, and especially experimentation with emerging technologies. So given the prominence of artificial intelligence and the way that it is shaping our lives in, you know, everything from the, you know, ads you get served on your phone to Netflix recommendations to other things, we wanted to try to understand those attitudes.
So, working with an organization called Civic Pulse, we surveyed almost seven hundred local officials during October 2020, so in the run-up to the 2020 presidential election. And we actually got a lot of responses. We had, you know, over 550 people that completed the full survey, along with another set of people that partially completed the survey.
And so we actually think we have a lot of insights we can share then about the way that people think about, at the local level, artificial intelligence. And we think that this is important, because a lot of the decisions about actual adoption and use of AI will be made by all of you, will be made by people who are working at the state and local level, thinking about, you know, everything from business regulations in general, regulations on automobiles, regulations on the police, regulations on other kinds of institutions, both government institutions and in the private sector.
And it’s also important to try to understand this in the local-government context because of the way the private sector is driving a lot of the innovation in AI. You know, it’s almost a truism at this point to talk about the way that technology advances faster than our ability to figure out what to do about it. But that’s been especially true in this context.
And I want to tell you a little bit about the sort of key takeaways we had from the survey before turning it over to Lauren to talk more about some of the specific results and some of the specific results involving facial-recognition technology, which I know is, you know, obviously on everybody’s mind as a key potential application of AI.
The first thing we found was certainly, I would say, a familiarity effect in that those who considered themselves, through their careers or through their knowledge, to have a baseline understanding of, you know, what AI is—and you think about AI here as computers doing tasks that we used to think required human intelligence—that the more familiar people were with these—with AI—the more likely they were to be supportive of using AI in a variety of different kinds of application areas.
The second was those that were most concerned about AI and uses of AI tend to be concerned with tradeoffs, you know, maybe even recognizing the potential benefits of having algorithms making choices or advising decision-makers, but they were really worried about bias and the way that, you know, all the biases that affect us in our daily lives can spill over into algorithms and then generate biased outcomes, as well as loss of privacy.
I mean, the engine of our big-tech companies, as incredible as they are, were sort of built on taking all of our information and putting it in enormous databases that they then use to further refine their products. And we’ve agreed to do that in all the user agreements that we accept every time we sign up for one of these services or get a new phone, which I did last weekend. It had to accept, you know, fifty new different things. And that’s raised a lot of privacy concerns then when we think about the way that algorithms are aggregating all that data and then in the way that companies might be using it.
And then the last thing I’ll say before turning it over to Lauren is that we found that support for facial recognition in particular, which is, you know, obviously a prominent application area, really seemed to depend for our respondents on the context in which it was being used.
And then we saw a lot of support for using facial recognition to say—to identify criminal suspects, which, to be fair, is actually a controversial use that we can get into, as well as for something like, say, the U.S. military to do surveillance; so, say, surveillance uses by the military, by—of criminals, et cetera. That was the area where our local-officials survey pool was pretty supportive.
They were a lot less supportive when asked how they thought about essentially surveillance of the general population, you know, ubiquitous cameras around gathering data on people that then, you know, all would be kind of fed into—you know, into algorithms. The local-official population, we found, was a lot less comfortable with that.
Now, to talk about some of those results in more detail, let me turn it over to Lauren.
KAHN: Awesome. Thanks, Mike.
So starting off here, we asked more than just racial-recognition technology. So I’ll just take you through these quickly. But we asked respondents to give their opinions on each potential use of AI on a scale from, you know, very supportive to no opinion to very unsupportive, very opposed to the technology use.
And so these included surveillance of criminal suspects through facial-recognition software and other means, general monitoring of the civilian population for illicit or illegal behavior, job selection and promotion for local officials, decisions about prison sentences, decisions about the transplant list, natural-disaster impact planning, responding to 9-1-1 calls, surveillance of monitoring and military targets, and the use of military force.
And here you can see the range on overall net perception, which means overall how positively or negatively these applications were viewed when taken in the aggregate. And they ranged from, you know, most opposed to most supportive, from the top to the bottom.
And so in the graphic here you can see the distribution and then you can see that, you know, from the range of applications, they vary from pretty controversial to pretty uncontroversial. Things like, you know, natural-disaster impact planning were pretty well supported. But then you get to some differences when you get to other issues; you know, when we talked about, you know, facial-recognition technology in particular.
So looking at the three technologies that I would say that would conceivably use facial-recognition technology of the general monitoring of the population, which was very, very unpopular, with about, like, negative 27 percent, so everyone was relatively opposed to that. And then you get to—on the flip side, you have surveillance of criminal suspects with facial recognition, which was pretty supported at 20 percent, and then surveillance and monitoring of military targets, which was very supported at 38 percent.
And so you can see that it really, really depends on the context of which of these technologies are used that actually deem how supportive—how much officials supported them. And so, you know, when it comes to their own populations and just, you know, run-of-the-mill just surveilling everybody, that was very controversial and very strongly opposed. But when you get to outside of the United States and specific-use cases that have a little bit more limitations, they were a little bit more open.
So Mike, if you want to move to the next slide. Awesome.
So here I’ve highlighted, to focus here, if you want to focus to the left, about what are the kind of indicators that led to people being more supportive or less supportive of facial-recognition technology. And so here age was an indicator of how supportive anything with a checkmark was. So if you were older, even though our population was a little bit skewed more older, just based on who we were sampling, but they were more supportive overall of facial-recognition software being used.
You also got political party being an indicator, with Republicans and Republican-leaning independents being more likely to support the use of AI in facial-recognition surveillance for criminal suspects and the use of military force. However, we see that jumping out again where that really—when it comes to what determined whether or not someone was supportive of facial-recognition technology was how concerned they were over the potential—excuse me—for algorithmic bias and the tradeoffs between potential privacy concerns and gathering information. And so those people who were really a lot more concerned, you know, prioritized privacy and were really concerned about bias were significantly less likely to approve of uses of AI in most areas, and especially facial-recognition software.
So if you want to hop to the next one, Mike. Thank you.
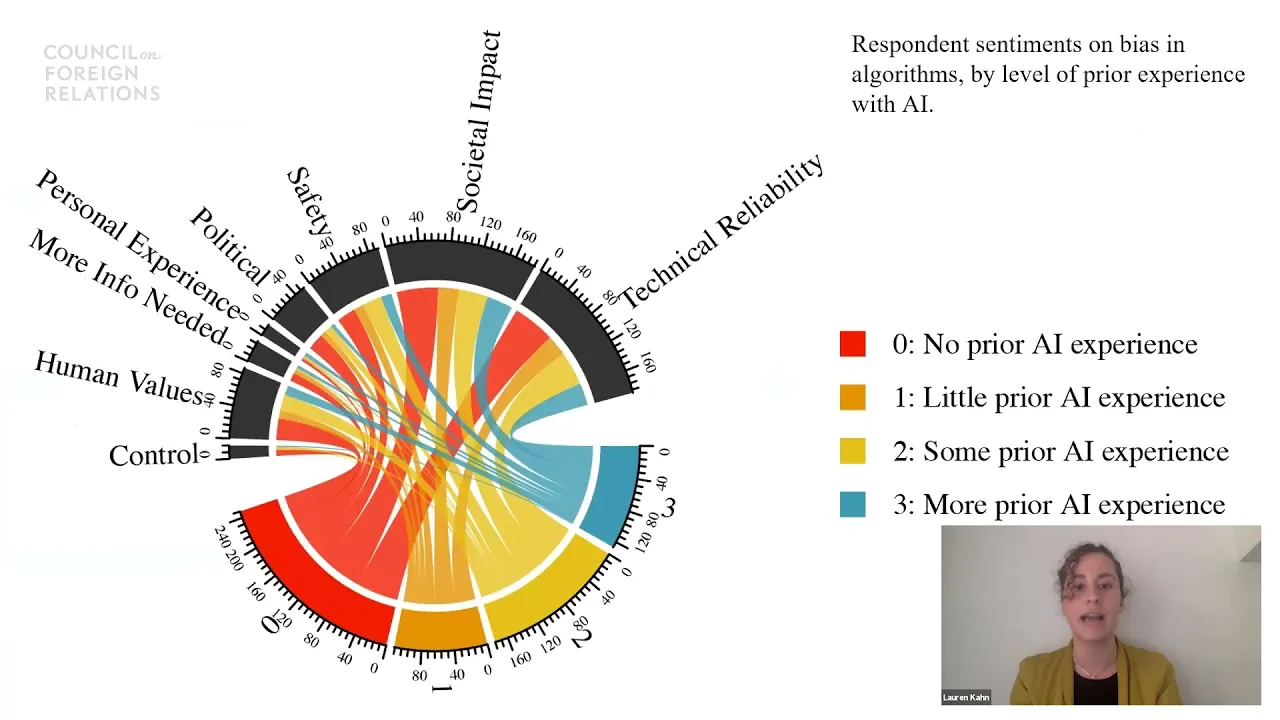
And so, finally, giving—a little bit unpacking this, you know, we’ve mentioned that, based on level of experience with AI, like familiarity, if you’re more experienced with AI, you tend to be more supportive. But then you also have this dynamic where if you’re also aware of AI, you also might be aware of its potential pitfalls as well as the benefits, right? You might be aware that, you know, anything—you know, they say garbage in, garbage out. If you have biases incorporated into the technology themselves, they might not work as properly and cause some ethical concerns as well.
And so we wanted to dig into that dynamic a bit, and we broke down to the text responses that respondents gave us for why they said they either opposed or supported the technology. So this doesn’t indicate whether or not they were supportive or not, but rather indicates what kind of logics and reasonings people were using in those open-text responses to describe why they were feeling the way that they did about specific uses of artificial intelligence.
And so when it came to concern about bias, they were really concerned, as you can see here, about the technical reliability, which means, like, will the technology actually function the way it’s meant to; and so, you know, whether you could avoid some of the issues like that bias might be caused—you know, AI in a lot of the facial-recognition technologies are known to not work as well of people with darker skin tones, for example, and people of color.
And so that’s a concern there; and then also about the societal impact, so about the implications of the technology not actually functioning properly, right; like, it might have significant ramifications if you use it for things like deciding prison sentence(s) of civilian populations and trying to identify individuals.
And so those are the two main logics, it seemed, that people were using. Another one was human values or concerns about, you know, these are, like, human decisions and humans really should be the ones making these choices, and so concerns about delegating these kinds of tasks in traditionally human-held roles to now artificial intelligence and algorithms. And so that was a little bit more about the details.
But I think we’re ready for questions now.
FASKIANOS: Fantastic. Thank you both; really interesting data and analysis.
And let’s go to all of you for your questions. You can raise your hand by clicking on the raised-hand icon. I will call on you and you can accept the unmute prompt and state your name and affiliation, and location would also be helpful, as well as your question. You may also submit a written question via the Q&A feature on your Zoom window. And if you do that, it also would be great if you could identify yourself. We do have a roster, but it’s helpful for me, who’s reading out the questions.
So don’t hold back. We really want to hear from you and maybe hear things that you’re doing in your own community as well.
So I’m going to go first to Dr. Brad Lewis.
Q: Hi. Thanks for the presentation and thanks for taking my question. I guess one’s a question and one’s a comment.
You noted that surveillance of criminal activity was pretty well accepted and military was very well supported. But the numbers only came in at 20 and 38 percent. No criteria for AI had a majority opinion under any circumstance. That would be my first comment.
My second was, for the criminal activity, what defines a criminal? Am I a criminal if I get a parking ticket? That’s a pretty broad range of surveillance. I don’t know what criminal means.
FASKIANOS: And you’re coming from Ohio, correct? Chief medical officer in Ohio?
Q: Right. I’m chief medical officer for the Bureau of Workers’ Compensation. And in past lives I was also a city councilman and a county coroner.
FASKIANOS: Thank you.
Whoever wants to take that, or you both can.
HOROWITZ: Sure. I can jump in.
So to—so Dr. Lewis, it’s a great question. And the numbers that we gave you were actually the net level of support or opposition. And so one way to think about it is that, you know, essentially, like, 60-something percent of people were supportive of the—of using facial recognition involving, you know, criminal suspects, and even a little bit higher for surveillance of military targets, whereas about—whereas I think 70 percent of people were basically opposed to sort of general-population surveillance. What we were presenting you was the sort of net level of popularity or unpopularity. But maybe we can change that up next time.
The—your question about sort of what is a criminal actually is a really good one. I mean, for the purpose—I’ll say for the purpose of the survey, we didn’t actually define that. We wanted people filling it out to use whatever definition that they would use in their communities, understanding that that might actually differ a little bit.
But, you know, this to me is one of the big challenges when it comes to—when we think about applications of, say—I’ll continue using the example of facial recognition—when we think about the uses of facial recognition in the sort of police context. I mean, for decades you’ve had, you know, something like—you know, the FBI has had, say, databases of, you know, photos. And you’d say, like, all right, well, like, here’s a criminal suspect, and all right, like, let’s look through a book and see if we can find, you know, who the person is. I mean, that’s in some way like what a lineup is about, at the end of the day, like in a police station.
The, you know, use of facial-recognition software is designed to basically give you the ability—and a lot of local and state police have been, you know, taking advantage of this—to then go through, you know, thousands and thousands of different, you know, pictures almost at—you know, almost instantaneously. And the upside of that is that when it works, it gives you the, you know, ability to potentially more quickly—to try to figure out, all right, who this suspect might be.
The disadvantage can be when—that these—you know, that algorithms are probabilistic. You know, they’re not—they’re not calculators. So they tell you that there’s—all right, there’s a 75 percent chance that, you know, these—you know, the person in picture A and the person in picture B are the same. But that means one out of four times it’s wrong. And so just relying on those kinds of algorithms then can be sort of—can be potentially risky from a decision-making process, and there are then questions about how we think about that from an evidence perspective.
And getting back to your question about sort of what constitutes a criminal, how we think about the—you know, if there’s a facial-recognition match with, you know, somebody who stole a pizza once, like, did they—were they technically a criminal? Like, unless they got off with a misdemeanor, like, maybe. But the—but then, does that mean that we have a presumption of guilt about them? You know, it gets—it gets in some ways back to all the same questions that police and, you know, law enforcement have to—have to figure out in general. It’s just, you know, the algorithm becomes a—is a tool.
KAHN: Yeah. I would just add that emphasis about, you know, the algorithm being a tool and these kind of technologies being a tool, we don’t want to leave—I think a good way of thinking about this moving forward and for regulation in particular is, like, using these things, again, as a tool whereas a human’s still making the call. So it’s not up to the algorithm to decide what’s a criminal or what’s not; it’s there to provide you with information to help make a better educated decision about whether or not that’s the case. And so I think that is—I think also what people are scared about is, you know, algorithms making those decisions for humans, and I don’t think that those are actually going to be used in those cases yet.
And the technology’s not quite there yet, I would say. As we’ve seen, you know, it doesn’t work the way we want it to work. We are incentivized for it to not be biased because, you know, if you have a biased algorithm, that means it’s not a correct algorithm, it’s not working at a higher accuracy level. And so it behooves us to kind of work that out and to, you know, take all of those recommendations from an algorithm with a grain of salt.
FASKIANOS: So I think that’s a great segue into the next question, a written question from Ron Bates, who’s a councilmember in Los Alamitos, California: “How might AI replace current city workforce?”
KAHN: I can jump in there. I would say, again, is, like, I firmly believe—and you know, again, I’m going to say this again—it’s like, algorithms and AI is a tool; it’s not—nothing, like, kind of replaces humans. We’re not at human-level machine intelligence yet. We don’t have robots thinking and being able to perceive the same way humans do. And so I think while certain jobs might shift, I think there will be use and ways moving forward for human-machine teaming.
HOROWITZ: I would just—I would just add to that. I mean, I think it’s a—I mean, my off-the-cuff answer would be not if local officials have anything to do about it, given the way that our survey data suggests or the opposition of local officials to using algorithms as things like to make decisions, say, about hiring and promotion.
But I mean, you know, like, jokes aside, we—you know, technological change changes the composition of the workforce, the—you know, the jobs that we need in the workforce, you know, how many people you need in a—you know, to make it run, you know, et cetera, all the—all the time. And it’d be—it’d be foolish to, you know, freeze in time our understanding of, say, what staffing a particular office should look like based on a snapshot of the—of technology—of technology then. I mean, think how much the composition of a lot of offices has changed even from—you know, say, like, from the ’50s to today or even from the ’80s to today.
So I think that there are probably some positions—there are some things, essentially, that automation and that algorithms can help address. And let me give you an example less from the city worker context, more from the—you know, think about the way that in the banking world the rise of automated trading algorithms and how that’s changed the composition of some banking workforces. You know, you’ve had—there actually aren’t necessarily a lot fewer jobs at some banks, but some of those jobs are different in that you don’t need someone to sort of call an execute a trade in the same way, and maybe you need fewer people doing some of the strategy on trades. But you do need a lot of oversight of those algorithms to make sure that they are performing—that they’re performing appropriately.
So I think it’s less that they will—you know, it’s not that the—it’s not that the algorithms are coming for our jobs, but they might change what some of those jobs are in a city. And the jobs that will be the least—you know, the jobs that are hardest to automate in some ways are the jobs that involve the least repetitive tasks and, you know, the highest level sort of cognitive judgment; whereas the more a task is just—you know, is, like, literally something one could imagine a robot doing, potentially, the easier it might be over time, potentially, for something to be automated. But even then, I don’t—I don’t think it’s necessarily, like, bad for jobs from a local-government perspective. I think what you’re talking about are potentially some different jobs and hopefully some technology, as Lauren said, to help people do their jobs more effectively.
FASKIANOS: Thank you. Going next to David Sanders, who has raised his hand.
Q: Thank you very much.
So I am a city councilor in West Lafayette, Indiana. We have recently had an ordinance to ban facial-recognition surveillance technology. I am the sponsor of that legislation. I will say I guess I defined the rules. I am a scientist at Purdue University, so I actually know quite a bit about AI, and I’m concerned about its—concerned about its power and its use in the hands of government, and it’s specifically a government ban. I should mention it passed twice because that’s the nature of the ordinance, and it was vetoed by the mayor. And the—even though the measure doesn’t mention anything about law enforcement or police—it just refers to government—it was the police that objected to the—to the ban on the technology.
So I had three questions I wanted—or three comments to which I’d like your response.
The first is: When you’re talking about the difference between trying to use facial recognition to look at criminal activity and then contrast that with the lack of support for continual surveillance, in fact, the looking for criminal activity is dependent upon the continuous surveillance which is occurring, which is through Ring systems or through people’s taking, you know, cellphone videos of everything that’s going on. So, actually, those things, there’s a—there’s a great disparity between the support for those two items, but in fact they’re the same thing. There is continuous surveillance going on because of the nature of society.
The second point that I’d like to make is that these are non-transparent commercial products which are being used for this surveillance. Neither the police nor the courts have any idea of what goes in that algorithm, and defendants have little or no way of finding out how those things were determined. And as you say—you’re correct in the sense that this is just one tool. There are other things that will—would go into a criminal case. But technology has a magical influence on, for example, jurors in a—in a court case. They tend to believe the technology. But in this case, as opposed to a technology like polymerase chain reaction, right, which is pretty readily understandable and you can actually go in and, you know, observe, you know, whether it’s being done correctly or not, this one is completely non-transparent.
The final point I’d just like to make—I know I’m taking a lot of time, but I want—I think these are going to be interesting topics for you to respond to—is the distortion of law enforcement which occurs with this tool. And I often compare it to the drunk underneath the lamppost, right? The drunk is looking—is under the lamppost. Policeman comes up to him and says, what are you doing? He says, I’m looking for my keys. So the policeman says, OK, I’ll help you. They look for the keys. They can’t find them. The policeman says, are you sure you dropped your keys over here? And so the drunk says, no, I dropped them over there. Why are you looking over here? Because the light is so much better over here. And so will this not—the fact that we have this technology, will it distort the nature of law enforcement? Will there be less, for example, interaction with the community to try to identify suspects and so on and more just reliance on this technology?
Thank you very much for your patience.
KAHN: Thank you. I think your latter two points about the distortion and transparency both kind of connect to something else Mike and I are very interested in, which is automation bias, which is the tendency for humans to cognitively offload the task to the algorithm, right? Like, if you have something that pops up and suggests, hey, look here, to just defer to that, rather than if you were going to just look yourself and didn’t have something pop up maybe you might have ended up there but, you know, you might have looked a few other places first, right?
And I think that gets to a really important part with training, which gets to another point where you mentioned about transparency and not knowing how these work, where people are just getting these technologies as a black box, don’t have a background, you know, in these technologies, don’t know how it works, and just like: Oh, look at this magic thing that it spit out at me. I love this. This is great. This is my answer.
And so I think a really important part there is then, again, if they do want to use these and do want to use these in a responsible way, that training and learning how these technologies work and then instituting transparency and checking measures is a really important part of that. Like I mentioned, it’s a tool. And I think it—while it has the potential to be dangerous, it also has the potential to be very helpful if used in the correct way. But that does require certain parameters and a lot of training and effort. So it’s whether or not they’re going to be able to be willing to kind of institute those measures to check themselves.
HOROWITZ: Let me—I agree with Lauren completely. And let me add a couple of things onto that.
I think your first question’s really interesting because it gets to the difference between the, you know, continuous surveillance by accident and continuous surveillance on purpose. You know, think about the difference between—you know, like, the difference between the U.S. and, say, like, the U.K. or another—or a country with, like, a CCTV system where, you know—you know, like in London or something, on every corner there’s, like, a camera. You know, that’s not the kind of—the kind of surveillance you’re talking about is some ways the surveillance that comes from the individual technology purchases that we’ve made and our individual choices rather than from a government decision to create general surveillance. And I think that there is a difference between those that’s worth—that’s worth keeping in mind.
But one of the things that I think ties together all three of your questions—and let me say, like Lauren did, I think that they are—these are really important, difficult issue. I mean, if they—we wouldn’t be having this conversation if they were easy to solve. And the—is that at the end of the day, to me, they’re all about people, in that the—like, the challenge of—like, the drunk under the lamppost story is a story about—is a story about, you know, the frailty of human cognition and the—and our—and our biases in the way that we make sort of judgments and then, you know, decide to—and decide to look for things. And the—you know, the story that you’re telling about the—about the court system is one about where under-resourced defendants often lack the tools to be able to respond to, you know, much better-resourced prosecutions. And the—you know, that can—that was true before AI, sadly, and that will be true in a world of AI.
Which means that, you know, I think—I think humans are both the problem and the solution here, and that the better we are at, you know, recognizing these biases, making good policy choices, et cetera, both with AI and with other things, the better that we would be—better we’ll be in using AI. And you know, whether that’s to the point that Lauren made about automation bias and treating the—treating the outputs of algorithms as probabilities, not as calculators, or thinking about the—or thinking about training and education to create more baseline knowledge of how algorithms work and their limits, you know, that’s the path forward. Like, otherwise, we’re—it’s humans that are going to make the mistakes.
FASKIANOS: Thank you.
KAHN: And what I will—sort of a little hopeful, hopeful thing is that, you know, states are and countries and technology companies, you know, and international organizations are all kind of realizing this, at least in some part, and are advocating for both, you know, explainable AI, transparent AI, and you know, are setting out ethics guidelines for themselves to start addressing and frameworks to start answering some of these questions.
FASKIANOS: Terrific. Thank you. Let’s go next, written question from Amy Cruver, and I don’t have an affiliation. But: “How easy or difficult is it to hack AI applications?”
HOROWITZ: Sadly, easier than one might think. I mean, the—why don’t we put it this way? Like, I don’t—we don’t have a—I think the—I think the issue is not the AI. Why don’t—why don’t we put it this way? The issue is sort of cloud applications in general and the number of people whose passwords are still 1-1-1-1 or their kids’ birthdays or—you know, like all of the basic cybersecurity issues that exist out there in the world and that make, you know, things hackable, say, in your house or elsewhere apply in a world of AI as well.
And I would add to that that the—you also have challenges where if you—you know, to Lauren’s point about sort of garbage in, garbage out, if you train an algorithm on data that’s inappropriate you’ll get outputs that aren’t as reliable. Or if you try to use an algorithm outside the context it was designed for, then it’s not—it’s probably—it’s not going to work very well. There are—you know, we can—I’ll save you from my speech about sort of military countermeasures and how—and how countries try to sort of spoof algorithms to fool sort of military AI, but there’s another issue there as well. I mean, maybe you could imagine criminals actually probably trying to do that, potentially. I don’t actually know.
But the—but I think that the—I think the short answer is algorithms are potentially hackable on the front end if the data is biased. They’re potentially hackable on the back end. But the way—the reasons why they’re hackable are similar to the reasons why lots of things are hackable in the—in the information age, which is, again—(laughs)—about our bad passwords and related issues.
KAHN: Yeah, I agree with a hundred percent everything Mike says. It’s really a matter of, you know, there’s—with any specific technology, there’s a unique angle in to make it break. If you really try to break it, you could probably break it. But I would say, yeah, it’s not significantly more vulnerable, in my—in my brain, than, like, anything else that we use as, you know, cloud technology or is on a cyber—is, you know, susceptible to cyberattack or data poisoning.
FASKIANOS: Great. Let’s go to Christopher Flores next.
Q: Hi, everyone. Thank you for the question. Christopher Flores from the city of Chino.
I read in your guys’ article—I forgot exactly where I read it, but—that there was a—there was more support for AI uses. And I think this mentioned, like, areas like transportation and traffic and public infrastructure. That’s a big topic here in the city of Chino right now, so I just wanted to ask if you guys can highlight why—you know, why is there more support in that? And I mean, what exactly does that look like? And I’m asking from a person who doesn’t really have any—much knowledge in AI.
KAHN: Yeah, absolutely. So I think some of this is actually really interesting. A lot of this varied. A lot of what at least I had seen during the research on, you know, specifically, like, autonomous vehicles in transportation and some of the traffic flow issues where a lot of people really highlighted in their answers the societal impact. And so the ability for, like, autonomous vehicles such as for people who can’t drive themselves to be able to be driven places, for people with disabilities, or to facilitate, you know, carpooling in efficient ways and to reduce strain on certain sort of infrastructures and to maximize the flow in and out of cities. So people are really highlighting, you know, the societal benefits that it would have, you know, to prevent drunk driving, that sort of thing in particular when it came to more vehicles and transportation, which I thought was very interesting.
On the flipside of that, most people—a lot of the troubles of that was, like, they’re worried about implementation, and how willing people would be to use that, and how, you know, people are kind of—people like to drive. They like to drive themselves. And you know, it’s something that a lot of people do, and so taking that away from people was a little bit of a concern.
But otherwise, in general, that seemed to be one of the more widely appreciative, I think because the benefits are so tangible, right? You can get in a car, in an Uber and kind of visualize what it would be like, OK, if an algorithm was driving me instead of another human being, or if I took a taxi. It’s kind of the same delegation. You’re still making that choice. So it’s not so much of a leap. So I think that’s why maybe it was a little bit easier and more well-supported than other sorts of realms.
HOROWITZ: Yeah. Just to add to what—to what Lauren said, you know, we definitely found that people who prior to the pandemic reported that they had used ridesharing apps pretty regularly were more likely to be supportive of autonomous vehicles, which I think makes sense if you’ve already made—you know, as Lauren said, if you’ve made the—you’ve already delegated in some ways the decision, you know, off of yourself.
And also, another, I mean, I guess—I don’t know, I was going to say fun fact. I don’t know if “fun fact” is actually the right word. But the—from the results there was that people in top auto-manufacturing states were also a little less supportive of autonomous vehicles, which I thought was interesting since we’ll still actually probably need lots of cars, even. But the—but I think that the—when we—if you—when we look at the mass—the, you know, horrific number of auto accidents and fatalities sort of every year, people want to believe that there’s a better way. But we also love driving. And so, I mean, and obviously, self-driving technology isn’t quite there yet, you know, media headlines aside. Like, arguably, not even close, depending on what, you know, some experts say. But the desire is there because the situation we exist in now, where you have sort of thousands and thousands of people that die every year in auto accidents, it seems senseless.
Q: Yeah. And, well, thank you for that. And I asked because one conversation we had at a—at a recent council meeting was the idea of extending a freeway—the 241 freeway—and what happens is, to do that, there has to be, like, nine or ten agencies involved in trying to get that done. And it’s, like, that’s—you know, I’m not sure how many; we’re looking at maybe ten, fifteen, twenty years down the road. And I mean, I look at, you know, these cars you guys are talking about and it’s like, well, there’s our answer. (Laughs.) You know, there won’t be any traffic jams on the 71 and the 91 anymore. But I don’t know. Thank you for your answers.
HOROWITZ: I think it—let me just add one other thing to that. I think it’s so—I think it’s a really interesting example, right, of how technology advance can advance faster than infrastructure or, you know, in our ability to—in our ability to respond. If it would take, you know, ten—I do not envy that job. If it would take ten regulatory agencies—and by the way, I’m sure you’re doing an amazing job—you know, ten regulatory agencies and fifteen to twenty years to, you know, like, add a lane to the—to the highway, and meanwhile, you know, technology’s continuing to advance and in ways that are not necessarily predictable, that actually creates a big challenge for then how to develop appropriate regulations.
FASKIANOS: I’m going to stay with the autonomous vehicle. So Chris Johnson, who’s CIO for the Maine secretary of state, asks if you can speak to the difference in using AI for assisting with analysis and probabilities of matches quickly, subject to human consideration, versus using AI for high-stakes decisions such—his example—do you run over the child or the adult when suddenly your vehicle has no path by which to miss both? Or, you know, would you have to crash into the vehicle beside you to avoid? And then, also, if you could just talk maybe a little bit about how the regulation of autonomous-vehicle technology differs from that of surveillance.
KAHN: Absolutely. That’s actually an interesting point because they’re based off of the same kind of technology, which is computer vision—you know, the ability for a computer to see with sensors, whether it sees roads or whether it sees humans. So it’s interesting that, like, the application here and how it’s specifically used really differs.
I would also say that when it comes to specifically the question of, you know, how do vehicles decide, you know, what kind of decisions to make, you know, in the moment that have human ethical ramifications, there is actually a very interesting study that we cited in the paper called the human machine—“Moral Machine”—
HOROWITZ: “Moral Machines,” yeah.
KAHN: —that, like, did a survey of, like, a hundred countries and had an enormous sample size. And you know, that was a—that was not a clear indicator, you know, given people situations of car. Like, if based on who’s in the car and who’s crossing the street and what you know about them, what kind of decision should the car make? And that actually really varies. It’s not a—there’s not a universal answer, right? That’s the classic trolley-car problem. And it varied a lot between different countries. You know, very—you know, United States in general had different answers than if you get to more—you know, when you have individualistic cultures versus collectivistic cultures, the answers really differed. So there’s no universal ethical, like, what should they do in this situation. And it’s like, do you maximize, you know, the potential for X or do you minimize the potential for Y.
And so I think that’s a really hard decision. And again, that comes back to what Mike had said earlier about, you know, humans are the problem but also humans are the solution there. It’s like whatever you put in, it’s still going to be a human value. And so deciding what those are will require a lot of self-reflection.
HOROWITZ: Yeah. I would just add to that that I think the—you know, we sometimes think about these choices as all or nothing, right? Like, either it’s a—it’s a self-driving car and, like, the car is choosing the, like, response in that crisis. You know, you—I think—I think it’s—if humans are—if we can get humans to continue to pay attention, it’s easy to imagine some sort—you know, hybrid kinds of options where you have cars that, you know, essentially are, you know, cruise control on steroids but in a—in a crisis situation are alerting drivers to take over. Because, you know, that—because that gets to that trolley problem question. You know, do you, you know, crash into the car next to you, run over a person, et cetera? You know, it gets to lots of questions about liability and insurance rates and, you know, who’s responsible for any harm that happens. And, like, those are—those are really complicated, then, regulatory questions as well that insurance companies, lots of, you know, state legislatures, et cetera, are going to have to work out.
FASKIANOS: So Tom Jarvey (ph) had raised his hand but lowered it, and so I just want to give the opportunity. I’m not sure if it was a mistake to raise it or to lower it, so. Great. Over to you.
Q: I’ll try and be quick because I might have a phone call coming here.
I just—I am totally off the subject of—(inaudible). Thinking of—the comment that was made earlier by the gentleman comparing PCR DNA testing to AI facial recognition had me thinking about the pros and cons of that, you know, realizing that DNA testing has, thankfully, exonerated many people who were wrongly convicted. At the same time, when we are—we do have a case where—and I am in law enforcement—where we do have a case where DNA is available, the pool that we test that against is a pool of largely previously convicted people. So, therefore, your chances of getting caught with DNA are greater if you’re already justice-involved. So I’m curious, thinking in the other direction, whether or not AI could be used to, in facial recognition, maybe balance that out if you have a larger pool. I would just like your comments on that, and I’ll mute now.
HOROWITZ: I mean, that’s a really tough question. I mean, in some ways it gets back to the—if you think about the way that you—you know, you train an algorithm on a—on a set of data. The broader the set of data is, the more diverse the set of data is, the more accurate your algorithm is probably going to be, whether you’re talking about, like, identifying cats or identifying people. And the—but it’s a—it’s a—it’s, like, the issue you raised is a huge challenge in that in some ways the pictures the police are most likely to have are going to be people that have been in the legal system in one way or another as well. And so the same issue that we have with DNA matching you could imagine with facial recognition, depending on what—and this is a place where you could imagine there eventually being federal regulation about this. You know, like, certainly the, like, big tech companies have enormous databases of all of our faces from the varieties of things that people do sort of on the internet in that—where we upload our pictures.
And so if you think about some of the controversies about Apple surrounding that from a couple months ago, the—so there is the potential for, then, say, like, a facial-recognition algorithm to draw on a broader database, why don’t we say, but whether they—people—you know, law enforcement should have access to that database is, I think, something that hasn’t been decided yet by our society, and where there are some real differences of opinion that get to, you know, real basic privacy questions. Like, if I haven’t been in the legal system, should some police department have my picture anyways? I don’t know. I mean, I could—I could see people making those arguments.
FASKIANOS: OK. Go ahead, Lauren.
KAHN: I just agree a hundred percent. And I think, you know, we probably sound like a broken record, but it again gets to, like, how you use it. And AI and especially, you know, computer vision and, you know, attempts to make cars that can see and, you know, algorithms that can see, it all depends on the dataset that you have. And that’s kind of how we operate now. It just seems a little bit more tangible because you’re physically collecting it, I would say, but it’s trying to make a representation of reality as close as you can as possible. So the bigger and bigger you get, the better your algorithms are going to be. But again, like, how much—how much do you want to actually grant that? How accurate do you want it to be? And how much do you want to forego? There’s going to be tradeoffs for anything, and again, it ties back to how much you’re willing to give up privacy and whether you use only publicly available sources, whether you are only limited to these sorts of sources or there’s, like, you know, state-approved datasets you can use. We’ll see how that kind of falls into place.
FASKIANOS: OK. So I’m going to take the next written question from Sanika Ingle, who is in the office of the Michigan House of Representatives: “What is being done to ensure AI technology is being executed without implicit bias? We have already seen the insidious”—insidious—“effects of AI technologies misidentifying suspects in criminal cases, not being able to collect accurate data when it pertains to people of color. Do you agree the development of AI technology is often at the expense of minority groups? And how do we address this?”
KAHN: Yeah. I would say yes. And we even see that in our, you know, data, where categorically women are less supportive of these technologies. And you know, some people might say, like, oh, they’re just not the tech bro interested in it, but I don’t think necessarily that’s the case. I think, you know, minority groups and women and other kind of groups of people will have ramifications that won’t necessarily impact, like, you know, other groups, where you’ve got—for example, if you feed a bunch of pictures to a training algorithm and say, like, these are all pictures of doctors, and a lot of them happen to be male and a lot of them happen to be, you know, not people of color, you’re going to get them—the algorithm thinking, oh, like, these are what all doctors look like, and excluding those types of people.
So I definitely think that it is a conscious thing that you have to do. And again, it depends how you’re training the data and who you have working in developing these technologies. And I think I’ve seen, you know, some technology companies in particular trying to address this and, you know, try to get better, but it’s a matter of we just need—we need more people in STEM, I think, in those kind of categories as well. And we should promote education to people to integrate them, because the people making these technologies will be the ones that shape how they work. So I think that’s an important part there.
HOROWITZ: Yeah, I agree with that. I mean, this is a question of how to—if the—algorithms trained mostly on sort of White men will be less effective at identifying any—less accurate at identifying anyone else, and we’ve seen this sort of time and again in facial recognition in, you know, anything from sort of academic research to some real-world criminal cases. And there are—I think there are pathways for those algorithms to improve. I also think there’s some degree of bias that might be inevitable just like in lots of non-AI areas there’s also bias.
FASKIANOS: I’m going to go to a raised hand, but I want to just quickly as this question from Richard Furlow, who’s the alderman-majority leader in New Haven: Do you know how many cities nationwide are using AI to identify criminal behavior?
HOROWITZ: The best data that I’ve seen—and Lauren can correct me if I’m wrong—if that the—about one in—I don’t know the—about one in four law enforcement—like, law enforcement communities, why don’t we say, sort of in America have access to facial recognition and are not prohibited from using it. Now, how many are actually using it on a regular basis I don’t know the answer to. But the—and this is not specific to cities. But the—but the stat I’ve seen is one in four.
KAHN: An important part to distinguish there is, too, is, like, when you get to artificial intelligence, it’s a—it’s a broad category, right? And when you get to facial-recognition technology, as we’ve seen over the course of this conversation, it’s broad.
And so, in addition to that, it’s hard to know exactly what they’re using them for. For example, there was a recent GAO report that, like, did a survey of, I think, like, twenty-four federal organizations and found that, like, you know, eighteen of them were using facial-recognition technology, but fourteen of those were people—they had given iPhones to their staff and, you know—you know, the iPhone now unlocks with your face, so that was considered facial-recognition technology. So I think the what and, like, how they’re using them is the really important part, and that I’m less sure on. So the one in four is a—is a guidepost that—yeah.
FASKIANOS: That’s for your next study.
KAHN: Yeah. (Laughs.)
FASKIANOS: Or survey.
HOROWITZ: Yeah.
FASKIANOS: You can add it to your list.
So I’m going to take the next question from Stephanie Bolton, who’s director of the Consumer Affairs Division of Maryland.
Q: Hi there. I am, yep, the director of consumer affairs for the Public Service Commission of Maryland. And in a previous role, I was law enforcement-adjacent.
And my question about AI kind of goes to witness identification and what kind of standards we hold our AI to. Witness identification of a suspect, especially a suspect of a different race, is notoriously lacking and has been for quite some time. There have been a number of studies in that realm. And I was wondering if, you know, hypothetically, if this technology should take off and AI can be used for facial recognition in criminal cases, are we going to hold it to the same standard that we hold, you know, human identification to, where we understand that there is room for error, especially when it comes to a(n) individual that maybe we don’t know, maybe we hadn’t seen before the incident? Or are we going to hold the AI to a much higher standard?
HOROWITZ: Thanks for your question, Ms. Bolton. I mean, I think—I think the honest answer is you’re probably going to make that decision, not me. And by that, what I mean is the—you could imagine a situation where, in an effort to conserve resources, you know, somebody—you know, we decided as societies at the local level that algorithms that were almost as good as people were OK. You could imagine a world where we decide as a society that we’re actually going to set the—we’re going to—we’re going to take the best research on the accuracy of people at, say, identifying, you know, a—you know, best data on witness identification and say an algorithm has to be as good as that. You could also imagine deciding that, you know, at the end of the day we’re a community of humans, and we want to be the ones making the choices, and so the standard that we would set for an algorithm actually needs to be, you know, 10 percent better, 20 percent, 30 percent better than people are because we’re, you know, removing humans from the process a little bit and so we want to affirmatively make sure that the algorithm is better. But I think that this is going to be a choice we will end up making, whether implicitly or explicitly, sort of at the ballot box and then through local regulation.
KAHN: Absolutely. And I think another point—like, not to—you know, we’ve talked a lot about the potential negative effects, which I think is very valid and we should be absolutely talking about these concerns. But the reason why we’re even discussing this in general is because the technology has shown to be, you know, really excellent in some situations and better than humans in some situations, which is why it’s appealing, you know, to free up space to do other things and to use humans for, you know, cognitively more demanding tasks, necessarily. And so I think making these calls is, like, it’s going to happen. It’s going to happen soon. And I think that is—these are very important questions to ask. But yeah, it is—it’s up to, you know, local and state legislators. They’re going to be the ones making the decisions.
FASKIANOS: OK. Putting the onus back on all of you on this call and your colleagues.
So I’m going to go next—and I know David Sanders has a follow-up question, but I want to try to get as many different voices in as possible. So we’ll try to get to you.
So Fazlul Kabir is a Council member from College Park, Maryland, and wanted you to talk a little bit about AI/machine learning-based smart predictive system in the area of crime trends, loss of tree canopies et cetera.
HOROWITZ: Yeah. I think that’s the—you know, an area where you would expect AI to do pretty well, are areas where you can, you know, aggregate lots of data and where we think that the dataset is pretty good, and then forecast. So I would actually think that tree canopies would be a pretty good use case for algorithms if you’re trying to—if you’re trying—you know, because you can—you could input all that data. You could actually—I mean, I could imagine how you’d do that, actually, pretty easily. So that, I think, is a good use case.
Crime trends, the—I mean, in some ways the—you—I think that the—it depends on how good you think the data is on where—on how—how good are sort our crime databases are and the extent to which you think that conditions in those—how static you think conditions in those communities are. The challenge is that as communities change, then models built on older data may be less applicable. And so that’s the kind of thing where you’d almost need to be—if you were going to do that, you’d need to be updating incredibly constantly to be able to make any, even, I think, pretty basic predictions.
I mean, that would be a pretty controversial use, I think, of AI. I don’t know. What you do you think, Lauren?
KAHN: Yeah, I would say so. But I—at the same time, it’s this is the part where you—it’s not really different than what people do already. If you’re talking about looking at data and seeing what’s happened in the past and trying to find indicators for, like, why X might have—might have happened or why Y might have happened, and then sticking that in a model, that’s not very—versus a human doing that or, like, you know, an algorithm doing that, it’s not really different, right? It’s crunching numbers.
And so I think it depends on, like, when you get to the after effect of the, like, OK, but, like, are you going to make decisions or make judgments based on that data that’s, like, projected, is that—and whether you’re going to have a human or an algorithm do it. That’s a little bit more tricky. But I think just for, like, guiding and research purposes, if you’re sticking an algorithm on, like, oh, like, where do we expect the trees to be—canopies to be in, like, ten years, or how do we project, you know, crimes going in this area and, like, what have the trends been, I think that’s a very, you know, different kind of use case versus actually making predictive, you know, choices or specifics about individuals versus aggregated data.
FASKIANOS: OK. I’m going to just quickly read this question from Lisa Gardner: “It sounds like AI may pose a replacement risk for the entry level and/or lower-skilled workforce. Would that be correct?”
HOROWITZ: I don’t think it’s lower skill. I think it’s about repetition of task. And you know, what—we as a society, we define what we think, like, is skilled or less skilled. You could imagine a lot of entry-level roles where the tasks one is doing are actually pretty diverse, both in sort of manual labor category and in the white-collar community. And so those would be actually, you know, potentially a lot more difficult to replace, whereas there could be people that are higher skilled but are basically, like, doing the same thing all the time and perhaps a computer could do it faster.
So the—I think it’s less about necessarily entry level and it’s more about repetition of task. And to the extent that one—there are some entry-level jobs where the tasks are very repetitive, those would be at higher risk. But the underlying thing is, I think, not about necessarily the, you know, sort of skill level.
KAHN: Right. Absolutely.
FASKIANOS: All right. Well, we are ending right on time. And I am sorry we could not get to the other questions in the Q&A box or raised hands, but we’ll just have to revisit this topic and also look for your next research paper and survey. And if you haven’t had a chance to read it, please do.
So, Michael Horowitz and Lauren Kahn, thank you again for sharing your expertise with us today.
And to all of you for your insights, your questions/comments, really appreciate it. Thank you for all the work that you’re doing in your local communities. And as you heard today, the decisions rest with you. (Laughs.) So we’re looking to see what you all do.
You can follow Dr. Horowitz on Twitter at @MCHorowitz and Ms. Kahn at @Lauren_A_Kahn. Of course, come to CFR.org to follow their policy and analysis, as well as our other fellows. And follow the State and Local Officials Initiative on Twitter at @CFR_Local, as well as go to ForeignAffairs.com for more expertise and analysis. Please do email us—[email protected]—with feedback or topics that you wish we would cover, speakers, et cetera. We’re all ears. We’d love to hear from you.
And thank you both again, and stay well, and stay safe, everybody.
KAHN: Thank you.
HOROWITZ: Thanks a lot.
(END)